


Gemini 2.5 Flash API is Google’s latest multimodal AI model, designed for high-speed, cost-efficient tasks with controllable reasoning capabilities, allowing developers to toggle advanced “thinking” features on or off via the Gemini API.
Overview of Gemini 2.5 Flash
Gemini 2.5 Flash is engineered to deliver rapid responses without compromising on the quality of output. It supports multimodal inputs, including text, images, audio, and video, making it suitable for diverse applications. The model is accessible through platforms like Google AI Studio and Vertex AI, providing developers with the tools necessary for seamless integration into various systems.
Key Features
Multimodal Input and Output
Gemini 2.5 Flash’s ability to process and generate multiple data types allows for comprehensive understanding and interaction. This includes interpreting complex visual scenes, understanding spoken language, and generating coherent responses across different media formats.
Enhanced Reasoning Capabilities
The model incorporates advanced reasoning mechanisms, enabling it to perform step-by-step analysis and deliver informed responses, particularly beneficial for tasks requiring logical deduction and problem-solving.
Optimized Performance
With a focus on efficiency, Gemini 2.5 Flash offers reduced latency and improved processing speeds, making it ideal for applications where time-sensitive responses are critical.
Technical Indicators
Reasoning ontrol
The “thinking budget” feature allows for fine-tuning the model’s reasoning depth, providing control over computational resources and outputquality.
Tool and AgenticSupport
Gemini 2.5 Flash includes improved support for external tools and agents, facilitating more complex task execution and integration into various orkflows.
Technical Specifications
- Input Context Window: Up to 1 million tokens, allowing for extensive context retention.
- Output Tokens: Capable of generating up to 8,192 tokens per response.
- Modalities Supported: Text, images, audio, and video.
- Integration Platforms: Available through Google AI Studio and Vertex AI.
- Pricing: Competitive token-based pricing model, facilitating cost-effective deployment.
Evolution from Previous Models
The Gemini Flash series has evolved to meet the growing demands for efficient AI mdels:
- Gemini 1.5 Flah: Introduced as a cost-effective solution with improved performance merics.
- Gemini 2.0 Flah: Enhanced speed and introduced native image generation capabilties.
- Gemini 2.5 Flah: Current iteration focusing on adjustable reasoning and multimodal suport.
Building upon the foundations of its predecessors, Gemini 2.5 Flash introduces significant improvements:
- Speed: Achieves up to twice the processing speed compared to earlier versions.
- Accuracy: Enhanced accuracy in tasks involving complex reasoning and multimodal data interpretation.
- Resource Management: Incorporates a “thinking budget” feature, allowing developers to balance computational resources and response quality.
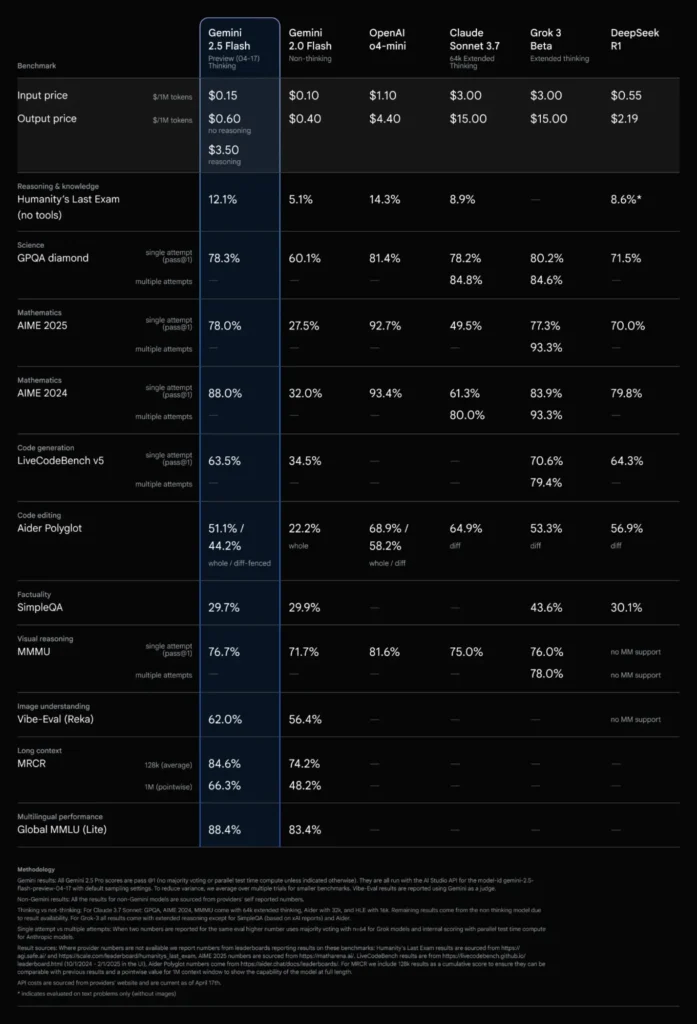
Benchmark Performance
Gemini 2.5 Flash demonstrates superior performance across various benchmarks:
- Humanity’s Last Exam (Reasoning & Knowledge): 18.8%
- Science GPQA (Single Attempt): 84.0%
- Mathematics AIME 2025 (Single Attempt): 86.7%
- Code Generation (LiveCodeBench v5): 70.4%
- Visual Reasoning (MMMU): 81.7%
- Multilingual Performance (Global MMLU Lite): 89.8%
These results indicate Gemini 2.5 Flash’s competitive edge in reasoning, scientific understanding, mathematical problem-solving, coding, visual interpretation, and multilingual capabilities
Application Scenarios
The versatility of Gemini 2.5 Flash makes it suitable for a wide array of applications:
- Customer Support: Automating responses to customer inquiries across various platforms.
- Content Creation: Assisting in generating multimedia content, including text, images, and audio.
- Data Analysis: Interpreting complex datasets and providing insights in real-time.
- Educational Tools: Developing interactive learning materials that adapt to different media formats.
See Also Gemini 2.5 Pro API
Conclusion
Gemini 2.5 Flash stands as a testament to Google’s commitment to advancing AI technologies. With its robust performance, multimodal capabilities, and efficient resource management, it offers a comprehensive solution for developers and organizations seeking to harness the power of artificial intelligence in their operations.
How to call Gemini 2.5 Flash API from CometAPI
Gemini 2.5 Flash API Pricing in CometAPI,20% off the official price:
- Input Tokens: $0.24 / M tokens
- Output Tokens: $0.96/ M tokens
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Useage Methods
- Select the “
gemini-2.5-flash-preview-04-17” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience. - Replace <YOUR_AIMLAPI_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
For Model lunched information in Comet API please see https://api.cometapi.com/new-model.
For Model Price information in Comet API please see https://api.cometapi.com/pricing.
API Usage Example
Developers can interact with gemini-2.5-flash-preview-04-17
import os
from openai import OpenAI
client = OpenAI(
base_url="
https://api.cometapi.com/v1/chat/completions",
api_key="<YOUR_API_KEY>",
)
response = openai.ChatCompletion.create(
model="gemini-2.5-flash-preview-04-17",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain the concept of quantum entanglement."}
]
)
print(response['choices'][0]['message']['content'])
This script sends a prompt to the Gemini 2.5 FlashGemini 2.5 Flash