
How to Use DeepSeek-V3.1 API — a practical developer tutorial

DeepSeek-V3.1 is the latest hybrid reasoning model from DeepSeek that supports both a fast “non-thinking” chat mode and a more deliberate “thinking/reasoner” mode, offers long (up to 128K) context, structured outputs and function-calling, and can be accessed directly via DeepSeek’s OpenAI-compatible API, via an Anthropic-compatible endpoint, or through CometAPI. Below I walk you through what the model is, benchmark and cost highlights, advanced features (function calling, JSON outputs, reasoning mode), then give concrete end-to-end code samples: direct DeepSeek REST calls (curl / Node / Python), Anthropic client usage, and calling via CometAPI.
What is DeepSeek-V3.1 and what’s new in this release?
DeepSeek-V3.1 is the most recent release in the DeepSeek V3 family: a high-capacity, mixture-of-experts large language model line that ships a hybrid inference design with two operational “modes” — a fast non-thinking chat mode and a thinking / reasoner mode that can expose chain-of-thought style traces for harder reasoning tasks and agent/tool use. The release emphasizes faster “thinking” latency, improved tool/agent capabilities, and longer context handling for document-scale workflows.
Key practical takeaways:
- Two operation modes:
deepseek-chatfor throughput and cost,deepseek-reasoner(a reasoning model) when you want chain-of-thought traces or higher reasoning fidelity. - Upgraded agent/tool handling and tokenizer/context improvements for long documents.
- Context length: up to ~128K tokens (enables long documents, codebases, logs).
Benchmark Breakthrough
DeepSeek-V3.1 demonstrated significant improvements in real-world coding challenges. In the SWE-bench Verified evaluation, which measures how often the model fixes GitHub issues to ensure unit tests pass, V3.1 achieved a 66% success rate, compared to 45% for both V3-0324 and R1. In the multilingual version, V3.1 solved 54.5% of issues, nearly double the approximately 30% success rate of the other versions. In the Terminal-Bench evaluation, which tests whether the model can successfully complete tasks in a live Linux environment, DeepSeek-V3.1 succeeded in 31% of tasks, compared to 13% and 6% for the other versions, respectively. These improvements demonstrate that DeepSeek-V3.1 is more reliable in executing code and operating in real-world tool environments.

Information retrieval benchmarks also favor DeepSeek-V3.1 in browsing, searching, and question-answering. In the BrowseComp evaluation, which requires navigating and extracting answers from a webpage, V3.1 correctly answered 30% of questions, compared to 9% for R1. In the Chinese version, DeepSeek-V3.1 achieved 49% accuracy, compared to 36% for R1. On the Hard Language Exam (HLE), V3.1 slightly outperformed R1, achieving 30% to 25% accuracy, respectively. On deep search tasks such as xbench-DeepSearch, which require synthesizing information across sources, V3.1 scored 71% to R1’s 55%. DeepSeek-V3.1 also demonstrated a small but consistent lead on benchmarks such as (structured reasoning), SimpleQA (factual question answering), and Seal0 (domain-specific question answering). Overall, V3.1 significantly outperformed R1 in information retrieval and lightweight question answering.

In terms of reasoning efficiency, token usage results demonstrate its effectiveness. On AIME 2025 (a difficult math exam), V3.1-Think achieved accuracy comparable to or slightly exceeding R1 (88.4% versus 87.5%), but used approximately 30% fewer tokens. On GPQA Diamond (a multi-domain graduate exam), the two models were nearly even (80.1% vs. 81.0%), but V3.1 used almost half the tokens as R1. On the LiveCodeBench benchmark, which assesses code reasoning, V3.1 was not only more accurate (74.8% vs. 73.3%) but also more concise. This demonstrates that V3.1-Think is able to provide detailed reasoning while avoiding verbosity.
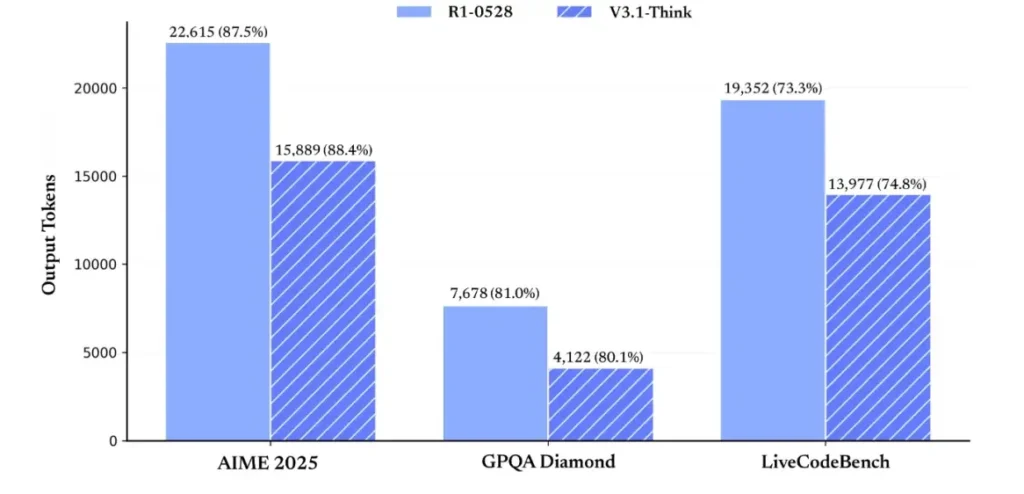
Overall, V3.1 represents a significant generational leap compared to V3-0324. Compared to R1, V3.1 achieved higher accuracy on nearly every benchmark and was more effective on heavy reasoning tasks. The only benchmark where R1 matched was GPQA, but at nearly double the cost.
How do I obtain an API key and set up a development account?
Step 1: Sign up and create an account
- Visit DeepSeek’s developer portal (DeepSeek docs / console). Create an account with your email or SSO provider.
- Complete any identity checks or billing setup required by the portal.
Step 2: Create an API key
- In the dashboard, go to API Keys → Create Key. Name your key (e.g.,
dev-local-01). - Copy the key and store it in a secure secret manager (see production best practices below).
Tip: Some gateways and third-party routers (e.g., CometAPI) let you use a single gateway key to access DeepSeek models through them — that’s useful for multi-provider redundancy (see the DeepSeek V3.1 API section).
How do I set up my development environment (Linux/macOS/Windows)?
This is a simple, reproducible setup for Python and Node.js that works for DeepSeek (OpenAI-compatible endpoints), CometAPI and Anthropic.
Prerequisites
- Python 3.10+ (recommended), pip, virtualenv.
- Node.js 18+ and npm/yarn.
- curl (for quick tests).
Python environment (step-by-step)
- Create a project dir:
mkdir deepseek-demo && cd deepseek-demo
python -m venv .venv
source .venv/bin/activate # macOS / Linux
# .venv\Scripts\activate # Windows PowerShell- Install minimal packages:
pip install --upgrade pip
pip install requests
# Optional: install an OpenAI-compatible client if you prefer one:
pip install openai- Save your API key to environment variables (never commit):
export DEEPSEEK_KEY="sk_live_xxx"
export CometAPI_KEY="or_xxx"
export ANTHROPIC_KEY="anthropic_xxx"(Windows PowerShell use $env:DEEPSEEK_KEY = "…")
Node environment (step-by-step)
- Initialize:
mkdir deepseek-node && cd deepseek-node
npm init -y
npm install node-fetch dotenv- Create a
.envfile:
DEEPSEEK_KEY=sk_live_xxx
CometAPI_KEY=or_xxx
ANTHROPIC_KEY=anthropic_xxxHow do I call DeepSeek-V3.1 directly — step-by-step code examples?
DeepSeek’s API is OpenAI-compatible. Below are copy-paste examples: curl, Python (requests and openai SDK style), and Node.
Step 1: Simple curl example
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat-v3.1",
"messages": [
{"role":"system","content":"You are a concise engineering assistant."},
{"role":"user","content":"Give a 5-step secure deployment checklist for a Django app."}
],
"max_tokens": 400,
"temperature": 0.0,
"reasoning_enabled": true
}'Notes: reasoning_enabled toggles Think mode (vendor flag). The exact flag name can vary by provider — check the model docs.
Step 2: Python (requests) with simple telemetry
import os, requests, time, json
API_KEY = os.environ["DEEPSEEK_KEY"]
URL = "https://api.deepseek.com/v1/chat/completions"
payload = {
"model": "deepseek-chat-v3.1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Refactor this Flask function to be testable: ..."}
],
"max_tokens": 600,
"temperature": 0.1,
"reasoning_enabled": True
}
start = time.time()
r = requests.post(URL, headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}, json=payload, timeout=60)
elapsed = time.time() - start
print("Status:", r.status_code, "Elapsed:", elapsed)
data = r.json()
print(json.dumps(data["choices"][0]["message"], indent=2))CometAPI: Completely Free Access to DeepSeek V3.1
For developers seeking immediate access without registration, CometAPI offers a compelling alternative to DeepSeek V3.1(Model name: deepseek-v3-1-250821; deepseek-v3.1). This gateway service aggregates multiple AI models through a unified API, providing access to DeepSeek and offering other benefits, including automatic failover, usage analytics, and simplified cross-provider billing.
First, create a CometAPI account at https://www.cometapi.com/—the entire process takes only two minutes and requires only email address verification. Once logged in, generate a new key in the “API Key” section. https://www.cometapi.com/ offers free credits for new accounts and a 20% discount on the official API price.
Technical implementation requires minimal code changes. Simply change your API endpoint from a direct DeepSeek URL to the CometAPI gateway.
Note: The API supports streaming (
stream: true),max_tokens, temperature, stop sequences, and function-calling features similar to other OpenAI-compatible APIs.
How can I call DeepSeek using Anthropic SDKs?
DeepSeek provides an Anthropic-compatible endpoint so you can reuse Anthropc SDKs or Claude Code tooling by pointing the SDK to https://api.deepseek.com/anthropic and setting the model name to deepseek-chat (or deepseek-reasoner where supported).
Invoke DeepSeek Model via Anthropic API
Install the Anthropic SDK: pip install anthropic. Configure your environment:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_API_KEY=YOUR_DEEPSEEK_KEYCreate a message:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="deepseek-chat",
max_tokens=1000,
system="You are a helpful assistant.",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hi, how are you?"
}
]
}
]
)
print(message.content)Use DeepSeek in Claude Code
Install : npm install -g @anthropic-ai/claude-code. Configure your environment:
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=${YOUR_API_KEY}
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chatEnter the Project Directory, and Execute Claude Code:
cd my-project
claudeUse DeepSeek in Claude Code via CometAPI
CometAPI supports Claude Code. After installation, when configuring the environment, simply replace the base URL with https://api.cometapi.com and the key with CometAPI’s Key to use CometAPI’s DeepSeek model in Claude Code.
# Navigate to your project folder cd your-project-folder
# Set environment variables (replace sk-... with your actual token)
export ANTHROPIC_AUTH_TOKEN=sk-...
export ANTHROPIC_BASE_URL=https://api.cometapi.com
# Start Claude Code
claudeNotes:
- DeepSeek maps unsupported Anthropic model names to
deepseek-chat. - The Anthropic compatibility layer supports
system,messages,temperature, streaming, stop sequences, and thinking arrays.
What are concrete, production best practices (security, cost, reliability)?
Below are recommended production patterns that apply to DeepSeek or any high-volume LLM usage.
Secrets & identity
- Store API keys in a secret manager (do not use
.envin prod). Rotate keys regularly and create per-service keys with least privilege. - Use separate projects/accounts for dev/staging/prod.
Rate limits & retries
- Implement exponential backoff on HTTP 429/5xx with jitter. Cap retry attempts (e.g., 3 attempts).
- Use idempotency keys for requests that may be repeated.
Python example — retry with backoff
import time, random, requests
def post_with_retries(url, headers, payload, attempts=3):
for i in range(attempts):
r = requests.post(url, json=payload, headers=headers, timeout=60)
if r.status_code == 200:
return r.json()
if r.status_code in (429, 502, 503, 504):
backoff = (2 ** i) + random.random()
time.sleep(backoff)
continue
r.raise_for_status()
raise RuntimeError("Retries exhausted")Cost management
- Limit
max_tokensand avoid accidentally requesting huge outputs. - Cache model responses where appropriate (especially for repeated prompts). DeepSeek explicitly distinguishes cache hit vs miss in pricing — caching saves money.
- Use
deepseek-chatfor routine small replies; reservedeepseek-reasonerfor cases that truly need CoT (it’s more expensive).
Observability & logging
- Log only metadata about requests in plaintext (prompt hashes, token counts, latencies). Avoid logging full user data or sensitive content. Store request/response IDs for support and billing reconciliation.
- Track token usage per request and expose budgeting/alerts on cost.
Safety & hallucination controls
- Use tool outputs and deterministic validators for anything safety-critical (financial, legal, medical).
- For structured outputs, use
response_format+JSON schema and validate outputs before taking irreversible actions.
Deployment patterns
- Run model calls from a dedicated worker process to control concurrency and queueing.
- Offload heavy jobs to async workers (Celery, Fargate tasks, Cloud Run jobs) and respond to users with progress indicators.
- For extreme latency/throughput needs consider provider SLAs and whether to self-host or use provider accelerators.
Closing note
DeepSeek-V3.1 is a pragmatic, hybrid model designed for both fast chat and complex agentic tasks. Its OpenAI-compatible API shape makes migration straightforward for many projects, while the Anthropic and CometAPI compatibility layers make it flexible for existing ecosystems. Benchmarks and community reports show promising cost/performance tradeoffs — but as with any new model, validate it on your real-world workloads (prompting, function calling, safety checks, latency) before full production rollout.
On CometAPI, you can run it securely and interact with it through an OpenAI-compatible API or user-friendly playground, with no rate limits.
👉 Deploy DeepSeek-V3.1 on CometAPI now!
Why use CometAPI?
- Provider multiplexing: switch providers without code rewrites.
- Unified billing/metrics: if you route multiple models through CometAPI, you get a single integration surface.
- Model metadata: view context length and active parameters per model variant.

