

The Qwen2.5-Omni-7B API provides developers with OpenAI-compatible methods to interact with the model, enabling the processing of text, image, audio, and video inputs, and generating both text and natural speech responses in real-time.
What is Qwen2.5-Omni-7B?
Qwen2.5-Omni-7B is Alibaba’s flagship multimodal AI model, boasting 7 billion parameters. Designed to process and understand multiple data modalities, it supports text, image, audio, and video inputs. The model facilitates real-time speech and video interactions, making it a versatile tool for various applications.
Key Features of Qwen2.5-Omni-7B
- Multimodal Processing: Capable of handling diverse inputs, including text, images, audio, and video, enabling comprehensive data understanding.
- Real-Time Interaction: Supports low-latency processing, allowing for real-time speech and video conversations.
- Thinker-Talker Architecture: Employs a dual-architecture system where the ‘Thinker’ manages data processing and understanding, while the ‘Talker’ generates fluent speech outputs.
- Time-Aligned Multimodal RoPE (TMRoPE): Utilizes TMRoPE for precise synchronization of temporal data across different modalities, ensuring coherent understanding and response generation.
Performance Metrics
Benchmark Achievements
Qwen2.5-Omni-7B has demonstrated exceptional performance across various benchmarks:
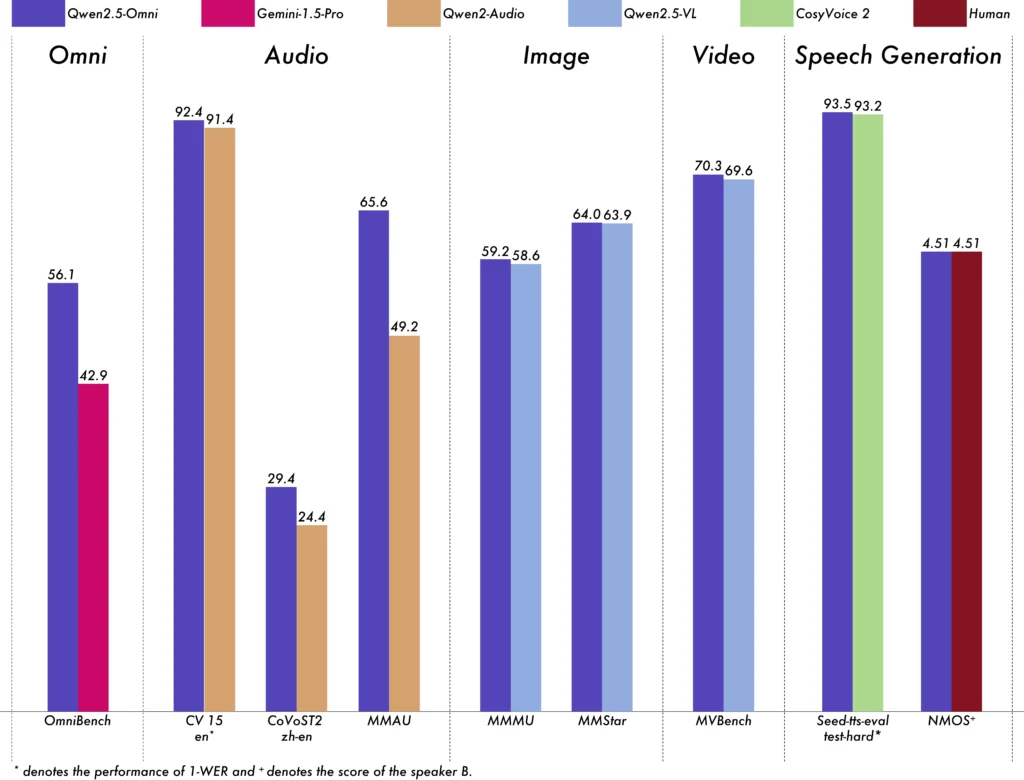
- OmniBench: Achieved an average score of 56.13%, surpassing models like Gemini-1.5-Pro (42.91%) and MIO-Instruct (33.80%).
- Speech Recognition: On the Librispeech dataset, it attained Word Error Rates ranging from 1.6% to 3.5%, comparable to specialized models such as Whisper-large-v3.
- Sound Event Recognition: Secured a score of 0.570 on the Meld dataset, setting a new benchmark in the field.
- Music Understanding: Achieved a score of 0.88 on the GiantSteps Tempo benchmark, highlighting its proficiency in music comprehension.
Real-Time Processing Capabilities
Designed for real-time applications, Qwen2.5-Omni-7B supports block-by-block streaming, enabling immediate audio generation with minimal latency. This feature is particularly beneficial for applications requiring prompt responses, such as virtual assistants and interactive AI systems.
Technical Specifications
Architectural Design
- Thinker-Talker Framework: The ‘Thinker’ component processes and understands multimodal inputs, generating high-level semantic representations and textual outputs. The ‘Talker’ converts these representations into natural, fluent speech, ensuring seamless communication between the AI system and users.
- TMRoPE Mechanism: Addresses the challenge of synchronizing temporal data from various sources by aligning timestamps of video and audio inputs, facilitating coherent multimodal understanding.
Training Methodology
The model underwent a three-phase training process:
- Phase One: Fixed language model parameters while training visual and audio encoders using extensive audio-text and image-text pairs to enhance multimodal understanding.
- Phase Two: Unfroze all parameters and trained on a diverse dataset comprising image, video, audio, and text, further improving comprehensive multimodal comprehension.
- Phase Three: Focused on long-sequence data training to bolster the model’s capacity to handle complex, extended inputs.
Evolution of Qwen Models
Progression from Qwen to Qwen2.5
The evolution from Qwen to Qwen2.5 signifies a substantial leap in AI model development:
- Enhanced Parameters: Qwen2.5 expanded to models with up to 72 billion parameters, offering scalable solutions for diverse applications.
- Extended Context Processing: Introduced the ability to process up to 128,000 tokens, facilitating the handling of extensive documents and complex conversations.
- Coding Capabilities: The Qwen2.5-Coder variant supports over 92 programming languages, assisting in code generation, debugging, and optimization tasks.
Advantages of Qwen2.5-Omni-7B
Comprehensive Multimodal Integration
By effectively processing text, images, audio, and video, Qwen2.5-Omni-7B provides a holistic AI solution suitable for a wide range of applications.
Real-Time Interaction
Its low-latency processing ensures immediate responses, enhancing user experience in interactive applications.
Open-Source Accessibility
As an open-source model, Qwen2.5-Omni-7B promotes transparency and allows developers to customize and integrate the model into various platforms without proprietary restrictions.
Technical Indicators
- Model Parameters: 7 billion
- Input Modalities: Text, Image, Audio, Video
- Output Modalities: Text, Speech
- Processing Capability: Real-time speech and video interaction
- Performance Benchmarks:
- OmniBench: 56.13% average score
- Librispeech (Word Error Rate): Test-clean: 1.8%, Test-other: 3.4%
Application Scenarios
Interactive Virtual Assistants
Qwen2.5-Omni-7B’s real-time processing and multimodal understanding make it ideal for virtual assistants that can see, hear, and respond naturally.
Multimedia Content Creation
Content creators can leverage the model to generate engaging multimedia content, combining text, images, and audio seamlessly.
Assistive Technologies
The model’s capabilities can aid individuals with disabilities, such as providing descriptive audio for visual content.
Usage Tips
Optimizing Performance
To achieve optimal performance, especially in real-time applications, it is recommended to utilize hardware accelerators and ensure sufficient GPU memory.
Integration with Existing Systems
Developers should consider the model’s input and output formats when integrating with existing applications to ensure compatibility and maximize efficiency.
Staying Updated
Regularly check the official repositories and documentation for updates and best practices to fully leverage Qwen2.5-Omni-7B’s capabilities.
Related topics How to Run Qwen2.5-Omni-7B Model
Conclusion
Qwen2.5-Omni-7B exemplifies the convergence of advanced AI research and practical application, offering a versatile and efficient solution for a multitude of tasks across various industries. Its open-source nature ensures that it remains accessible and adaptable, paving the way for future innovations in multimodal AI.
How to call Qwen2.5-Omni-7B API from CometAPI
1.Log in to cometapi.com. If you are not our user yet, please register first
2.Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
3. Get the url of this site: https://api.cometapi.com/
4. Select the Qwen2.5-Omni-7B endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
5. Process the API response to get the generated answer. After sending the API request, you will receive a JSON object containing the generated completion.