

Qwen2.5-VL-32B API has garnered attention for its outstanding performance in various complex tasks, combining both image and text data for an enriched understanding of the world. Developed by Alibaba, this 32 billion parameter model is an upgrade of the earlier Qwen2.5-VL series, pushing the boundaries of AI-driven reasoning and visual comprehension.

Overview of Qwen2.5-VL-32B
Qwen2.5-VL-32B is a cutting-edge, open-source multimodal model designed to handle a range of tasks involving both text and images. With its 32 billion parameters, it offers a powerful architecture for image recognition, mathematical reasoning, dialogue generation, and much more. Its enhanced learning capabilities, based on reinforcement learning, allow it to generate answers that better align with human preferences.
Key Features and Functions
Qwen2.5-VL-32B demonstrates remarkable capabilities across multiple domains:
Image Understanding and Description: This model excels in image analysis, accurately identifying objects and scenes. It can generate detailed, natural language descriptions and even provide fine-grained insights into object attributes and their relationships.
Mathematical Reasoning and Logic: The model is equipped to solve complex mathematical problems—ranging from geometry to algebra—by employing multi-step reasoning with clear logic and structured outputs.
Text Generation and Dialogue: With its advanced language model, Qwen2.5-VL-32B generates coherent and contextually relevant responses based on input text or images. It also supports multi-turn dialogue, allowing for more natural and continuous interactions.
Visual Question Answering: The model can answer questions related to image content, such as object recognition and scene description, providing sophisticated visual logic and inference capabilities.
Technical Foundations of Qwen2.5-VL-32B
To understand the power behind Qwen2.5-VL-32B, it’s crucial to explore its technical principles. Below are the key aspects that contribute to its performance:
- Multimodal Pre-Training: The model has been pre-trained using large-scale datasets consisting of both text and image data. This allows it to learn diverse visual and linguistic features, facilitating seamless cross-modal understanding.
- Transformer Architecture: Built on the robust Transformer architecture, the model leverages both the encoder and decoder structures to process image and text inputs, generating highly accurate outputs. Its self-attention mechanism enables it to focus on critical components within the input data, enhancing its precision.
- Reinforcement Learning Optimization: Qwen2.5-VL-32B benefits from reinforcement learning, where it is fine-tuned based on human feedback. This process ensures the model’s responses are more aligned with human preferences while optimizing multiple objectives such as accuracy, logic, and fluency.
- Visual-Language Alignment: Through contrastive learning and alignment strategies, the model ensures that both visual features and textual information are properly integrated in the language space, making it highly effective for multimodal tasks.
Performance Highlights
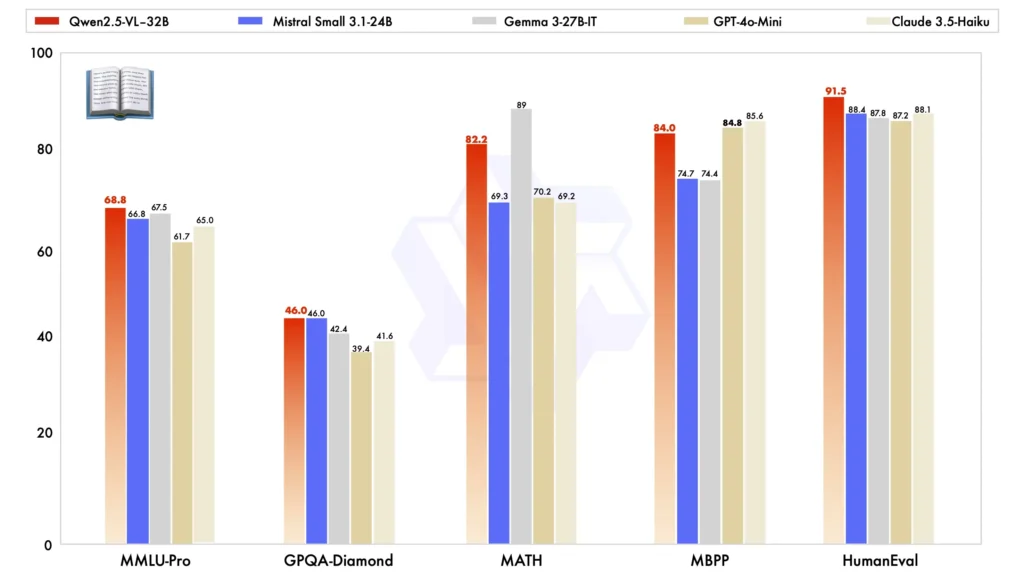
When compared with other large-scale models, Qwen2.5-VL-32B stands out in several key benchmarks, showcasing its superior performance in both multimodal and plain text tasks:
Model Comparison: Against other models like Mistral-Small-3.1-24B and Gemma-3-27B-IT, Qwen2.5-VL-32B demonstrates significantly improved capabilities. Notably, it even outperforms the larger Qwen2-VL-72B in various tasks.
Multimodal Task Performance: In complex multimodal tasks such as MMMU, MMMU-Pro, and MathVista, Qwen2.5-VL-32B excels, delivering precise results that set it apart from other models of similar size.
MM-MT-Bench Benchmark: Compared to its predecessor, Qwen2-VL-72B-Instruct, the new version shows significant improvement, particularly in its logical reasoning and multimodal reasoning capabilities.
Plain Text Performance: In plain text-based tasks, Qwen2.5-VL-32B has emerged as the top performer in its class, offering enhanced text generation, reasoning, and overall accuracy.
Project Resources
For developers and AI enthusiasts who wish to explore Qwen2.5-VL-32B further, several key resources are available:
- Official Website: Qwen2.5-VL-32B Project
- HuggingFace Model: HuggingFace Qwen2.5-VL-32B-Instruct
Real-World Applications
Qwen2.5-VL-32B’s versatility makes it suitable for a wide range of practical applications across various industries:
Intelligent Customer Service: The model can be employed to automatically handle customer inquiries, leveraging its ability to understand and generate text-based and image-based responses.
Educational Assistance: By solving mathematical problems, interpreting image content, and explaining concepts, it can significantly enhance the learning process for students.
Image Annotation: In content management systems, Qwen2.5-VL-32B can automate the generation of image captions and descriptions, making it an invaluable tool for media and creative industries.
Autonomous Driving: By analyzing road signs and traffic conditions through its visual processing capabilities, the model can provide real-time insights to improve driving safety.
Content Creation: In media and advertising, the model can generate text based on visual stimuli, assisting content creators in producing compelling narratives for videos and advertisements.
Future Prospects and Challenges
While Qwen2.5-VL-32B represents a leap forward in multimodal AI, there are still challenges and opportunities ahead. Fine-tuning the model for more specific tasks, integrating it with real-time applications, and improving its scalability to handle more complex multimodal datasets are areas that require ongoing research and development.
Moreover, as more AI models are released with similar capabilities, ethical concerns surrounding AI-generated content, bias, and data privacy continue to gain attention. Ensuring that Qwen2.5-VL-32B and similar models are trained and utilized responsibly will be critical to their long-term success.
Related topics:The Best 8 Most Popular AI Models Comparison of 2025
Conclusion
Qwen2.5-VL-32B is a powerful tool in the arsenal of AI models designed to tackle multimodal tasks with impressive accuracy and sophistication. By integrating advanced reinforcement learning, transformer architecture, and visual-language alignment, it not only surpasses previous models but also opens up exciting possibilities for industries ranging from education to autonomous driving. As open-source technology, it offers tremendous potential for developers and AI users to experiment, optimize, and implement in real-world applications.
How to call Qwen2.5-VL-32B API from CometAPI
1.Log in to cometapi.com. If you are not our user yet, please register first
2.Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
3. Get the url of this site: https://api.cometapi.com/
4. Select the Qwen2.5-VL-32B endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
5. Process the API response to get the generated answer. After sending the API request, you will receive a JSON object containing the generated completion.
